早上起来后查看了deepseek的后续报道后,又打开电脑确认了两件事情。
一是确认opencode在设置页面,提供商那里新增了“启用部署在中国的模型”选项,我跟外甥都记得昨天deepseek flash新版本发布前是没有的。
第二是看ccswitch版本更新了没有。果然深谙国情的ccswitch立即推出了二位小数点的版本优化,关键之处就是原生支持Responses API,说是三家国产网关经确定原生支持,但说到底还是因为deepseek。
同时,虽然opencode的模型部署在中国,但其支持的模型清单中,继Grok后,又新增了刚打骨折降价的GPT 5.6,而其小于272K tonkens只要0.2美元。
这是什么概念?就是廉价排名榜上至少排在deepseek flash和Mino后面。
这就跟外甥说的:美国人都要感谢deepseek。
分类: IT天地
提前开香槟的龙虾
这周开始辅导儿子往新笔记本上转移软件。昨晚安装MATLAB的时候,他突然问我现在龙虾怎么样了,我说快完蛋了。
没有安装测试过龙虾,一是因故错过了龙虾最火的时期,二是在Macmini被龙虾价格炒高后,听到龙虾作者那“mini配不上龙虾”的言论,顿时没了半点兴趣。
当一个agent狂妄到要力压大模型的时候,它的路子也就走到头了。最近腾讯把自家龙虾团队并入workbuddy,就是一个明证。
也正是龙虾的狂妄,给后来者指了一条明路,依靠大模型,提升自身性能,在服务中掌控而不是指派使用者,才是正道。
过早退场的flashget
在Lubuntu的笔记本同步Chrome后,连带着把之前的插件也同步过来了,其中就有AB download Manager,只是提示未连接。
本以为这是Windows下的软件,Linux下无法使用。但因为连续几次下载文件巨慢,便到其官网查看一下,居然也有Linux版本,下载安装,原先慢如蜗牛的下载,顿时飞了起来。
短视频平台上前几天还有一个怀旧视频,是怀念flashget的,夸赞它是一个跨时代的产品。的确,那曾经是超越蝙蝠和蚂蚁,成为装机必备的软件。
后来随着宽带的普及以及BT技术的流行,flashget也就停止更新退出历史舞台。只是没有想到,网络下载速度始终需要解决的问题。
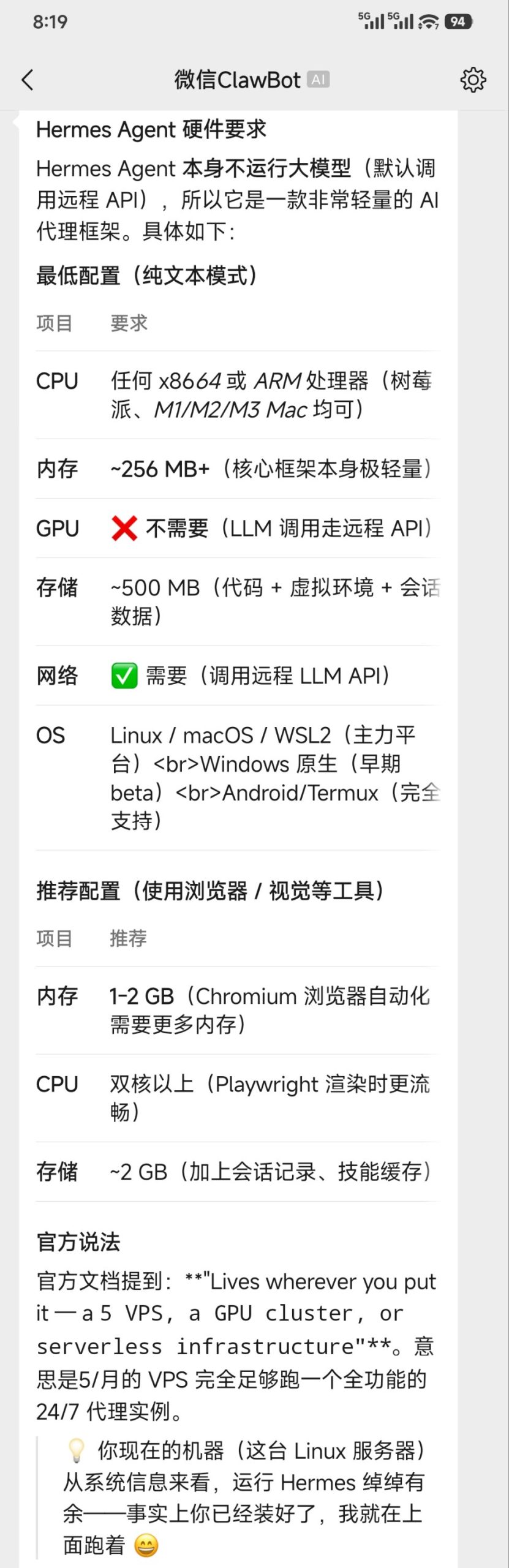
Hermes,退休笔记本是简易的家
龙虾刚冒头的时候,他还没大火,先把Macmini的价格炒上去了。其开发者更是豪言:Macmini配不上龙虾。
Hermes随后兴起,人家就谦逊多了,给个遮风避雨的住所运行就行。
本来用迷你主机后台运行Hermes,通过ssh操作。这段时间磨合后发现,如果作为工作主力而不是当做系统管理软件,还是用笔记本更为合适。因为Hermes如果管理资料,需要原始文件的输入以及生成资料的输出,有显示器的笔记本操作起来更为方便直观。
至于这样的笔记本,即便家里没有吃灰的,网上二手的,跟同档次的mini主机价格相差并不大。
而使用主力机运行Hermes,Mac系统还好说,至于Windows,总是信不过他。
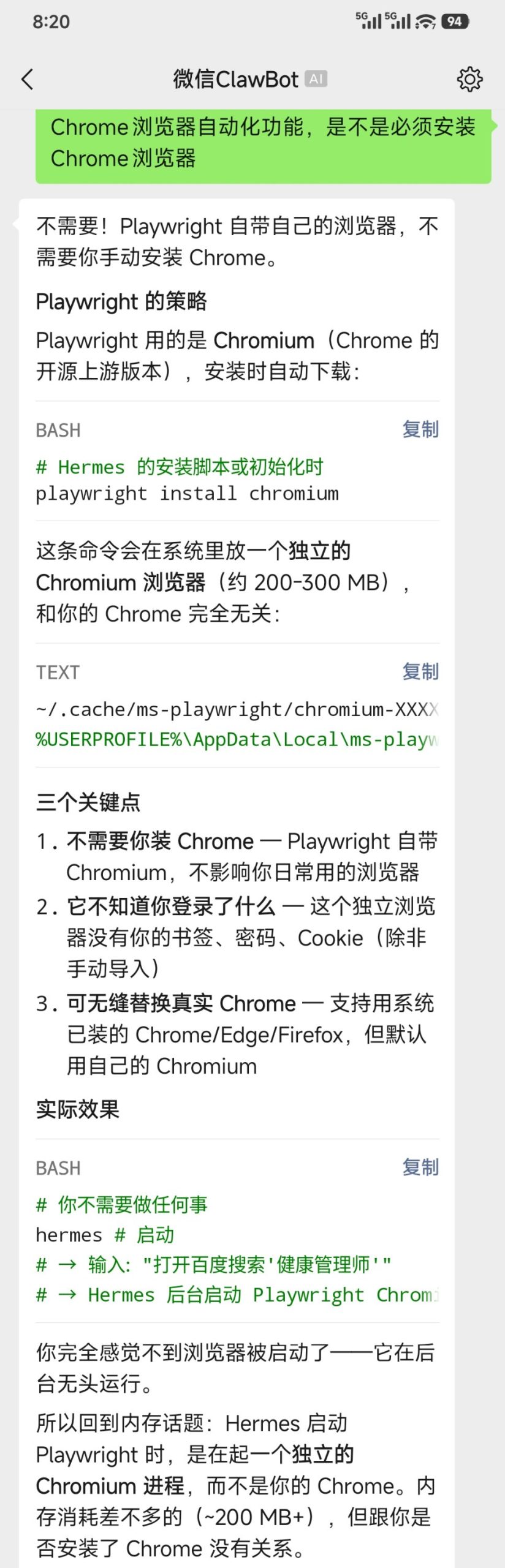
再无流量焦虑的opencode go
这几天短视频平台上比较热的话题是谷歌新推出的gemma4 12B开源模型,什么抛弃传统编译器,什么笔记本独显都能部署。
我连试着安装都没有,之前也安装过其4B,和26B模型,都没有媒体吹嘘那么神。
关键是,咱现在有opencode go。
原先我计划的是,本地模型进行数据量大、计算要求不高的本地文件处理,deepseek负责进一步的分析与归档。因为虽然有缓存命中这更低的价格再折扣,但毕竟这计价标准谁也看不懂。
但自从订阅了opencode go,尤其是通过CC swictch解决了Codex的第三方模型接入后,这token真是用起来跟不花钱一样了。
即便是每个月10刀。
至于本地模型,还是交给MInerU这样的定向模型吧。
名不虚传MinerU
最近每天刷抖音有些心安理得了,因为刷到AI相关视频占了多数。
不过这些视频很少看完,大多数也只是了解一下当索引,有的一听那高高在上的腔调直接划走。而这些划走的内容中,开篇一半都是什么项目在GitHub霸榜,或者暴涨多少星。我跟外甥交流中说到,这GitHub的星,快被中国人玩坏了。
昨天中午刷到一个类似视频没有划走,是因为这个叫MinerU的开源项目是关于OCR的。而就在上午,我在把前天同样PDF让豆包转换的时候,发现豆包变懒了,只转换了一半。
看来豆包收费后偷工减料的臆测也不是空穴来风。于是放下手机打开电脑开始查询MinerU,第一眼看到是国产的时候,并没有太大期望值,毕竟已经有百度的paddle在那里横着呢。
试着手机注册后在线转换了一个文件,结果让我完全意外,不止是接近豆包的转换效率,更是因为他的大方——无论是每天转换的限额,还是单个文件的大小。
按捺激动心情,立马在本地部署,不到6G的显存占用,却得到了完全可以接受的结果。
百度啊,又……
AI非助理
虽然脑子折腾大半晚,但昨天让Hermes开工的时候,心里还是没底。所以首先让Codex打头阵,利用前几天生成的skill,把一份国民体质监测标准的PDF文件转为MD文件。
这份PDF文件不是图片转换的,但图文、表格混编且有水印,不过效果还好,这skill还是效率高。
然后把MD文件交给Hermes进行分析归档,其后她的效率完全超出我的想象,Hermes不止是归档文件,还能预判需求,自行进行数据处理验证。我需要做的只是纠正MD转化过程中不规范的文本格式而已。
而即便是这些原始错误,提出纠正方案后,Hermes自己也可以根据前后文进行自我纠正并数据验证。
此前看到过一个评论,观点是控制欲强的人不适合用AI。的确,那跟武大郎开店差不多。
AI不能被称为助理,即便不能称为合作伙伴,但至少是一个能干价钱又合适的乙方。
Claude的傲慢
昨天测试PDF转markdown文件,先后使用了Codex、Hermes、opencode,在明确使用paddleOCR的API接口,而大模型同为ds4flash的情况下,转化的结果三个都大差不差,还算满意。
今天早上起来想起,测试了三个,还缺了一个Claude code,于是在同样条件下,使用同样提示词让Claude也转化一下。
跟网上评论的差不多,转化过程Claude要繁琐得多,期间甚至出现内存不足的情况,四核CPU全部满载,而最后的结果,可以用惨不忍睹来形容。
于是我质问Claude:你是用我的提供的API接口转化的吗?
Claude检查一下,承认自己没有遵照我的指令,是自作主张用的本地paddleOCR库,然后重新开工。最后结果也与其他agent相同。
看来,最近Codex装机量暴增,不止跟能否接入第三方大模型有关。
Claude这傲慢早晚要付出代价。
豆包,图像OCR王者
昨天跟外甥交流的时候提到微软的markitdown,当时我说没有宣传的那么神,不止是由图片转换的PDF文件,就算是word文档,转换出来也是一言难尽。
今天还是想进一步测试一下,发现问题主要还是出在OCR上,于是就开始测试了下各OCR模型及相关服务,试来试去,还是百度家的paddle相对堪用,免费且额度足够,也不能要求太高。
当然,这要跟谁比,把同样13M的PDF文件扔给豆包,基本上是秒回,里面无论结构还是引用符号,基本算是完美了。把他扔给Codex和Hermes,他们也是自愧不如。
所以我一直认为,如果豆包能够解决文档本地化处理而非上传,每个月68块钱的收费我是毫无意见的。
只是,这豆包的交流水平,实在是……


Linux系统管家,Hermes可堪重用
CC Switch的最新版本看来是一个重大的更新,今天看抖音上不断蹦出Codex接入deepseek模型的视频。
不清楚直接接入deepseek,跟接入opencode go是不是有区别,感觉很多视频是存在问题的,少了profile的参数。
不过也不重要了,在接入用着似乎不花钱的opencode go成功后,我重新切回了Hermes,还是她用起来亲切。
昨天去理发,排在店里几个山财留学生后面,便询问了Hermes配置要求。可能好久没有微信交流了,Hermes非常热情,一个劲地推荐自己能干价低。
如此看来,在接入外部模型的情况下,服务器安装一个Hermes当管家非常合适。