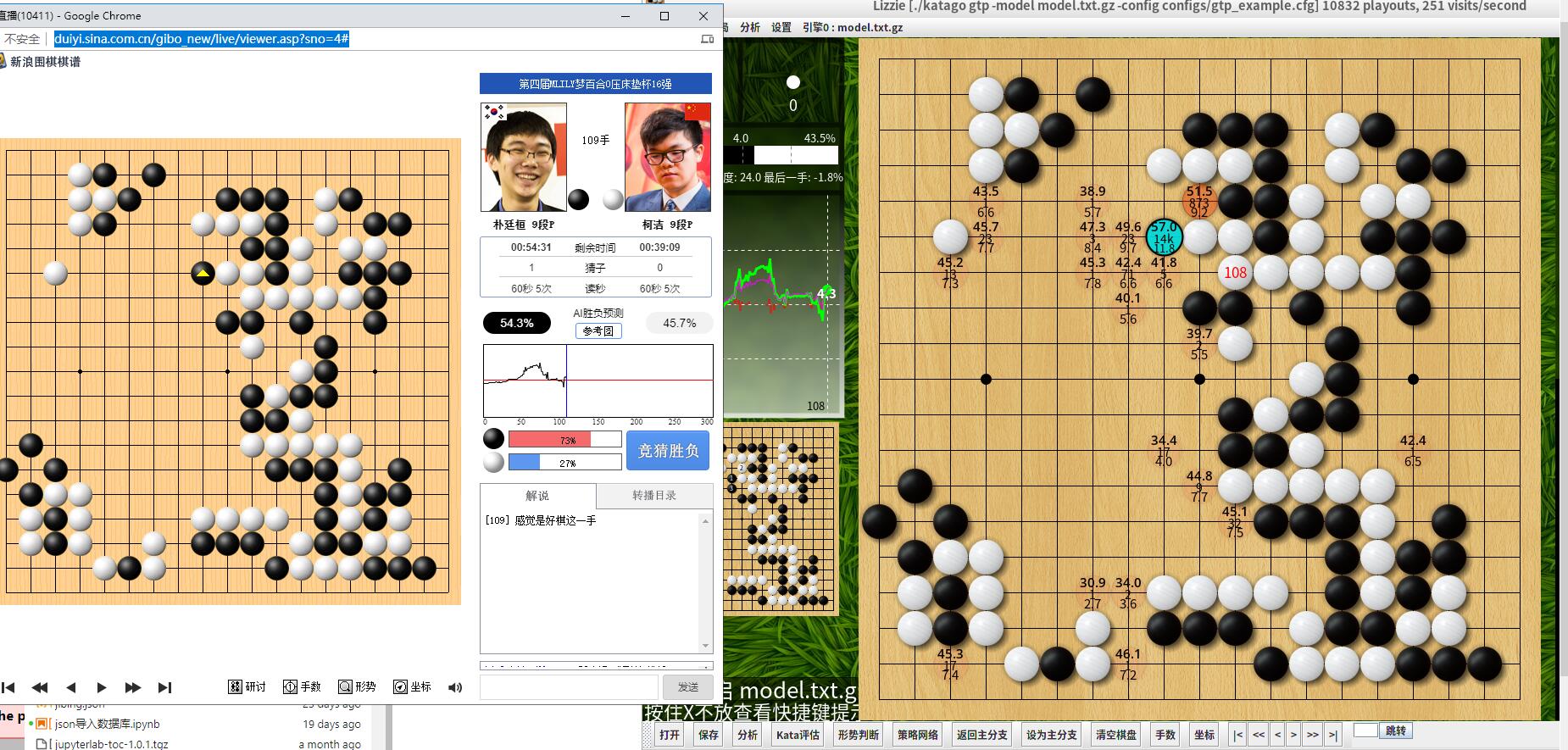
下午通过新浪观看了梦百合十六强战柯洁对朴廷桓的对局,这已经是当今顶尖棋手的对决了。观战同时把矿卡机打开,通过lizzie调用katago对棋局进行了同步分析,算是对katago能力的再次确认。
新浪的棋谱直播同时不但提供了AI的胜率分析,甚至提供了AI的变化参考图。这样解说员的工作就非常简单了,开始有些类似日本的观战记者那样,主要交代比赛细节了,什么柯洁喝什么,穿什么等等。
不知道新浪用的是什么AI,但水平肯定差不了。katago的硬件虽然寒酸了点,但整体表现不错,虽然胜率分析与新浪AI略有差异,那只是数字而已,优劣势分析还是靠谱的,尤其是决定局势的关键棋的选点基本没有太大的偏差,算是经受了考验。
即便是新浪的专业服务器的AI,和前段时间三星杯唐韦星与朴廷桓对局一样,在涉及到杀棋的局势时,也会慢半拍。对局后半盘柯洁选择在左上角杀棋时,AI开始判断朴廷桓的胜率由不足两位数直线上升到48%,但随即逐步降低,回复到正常的胜率。也让人虚惊一场。
不知是偏重攻击,还是硬件落后,katago对这手棋的判断,倒也“冷静”。由此一战,katago算是经受考验,下一步就是再提升硬件,整理古谱理想的实现,就指望他了。