AMD果然推出了自己的AI模型,而且还是7B体量小语言模型。
AMD是作为硬件商,他才是最应该推出AI模型的。因为只有有了自己模型,才能根据自家硬件量身定做,否则在英伟达强势统治下,要么自家硬件跑不起来,即便跑起来了,性能低下,也等于砸自家招牌。
同样急需开发自家大模型的,还有高通。
至少,运行状态如温度、功耗等可控,抱着个火炉,性能指标有个P用。
分类: IT天地
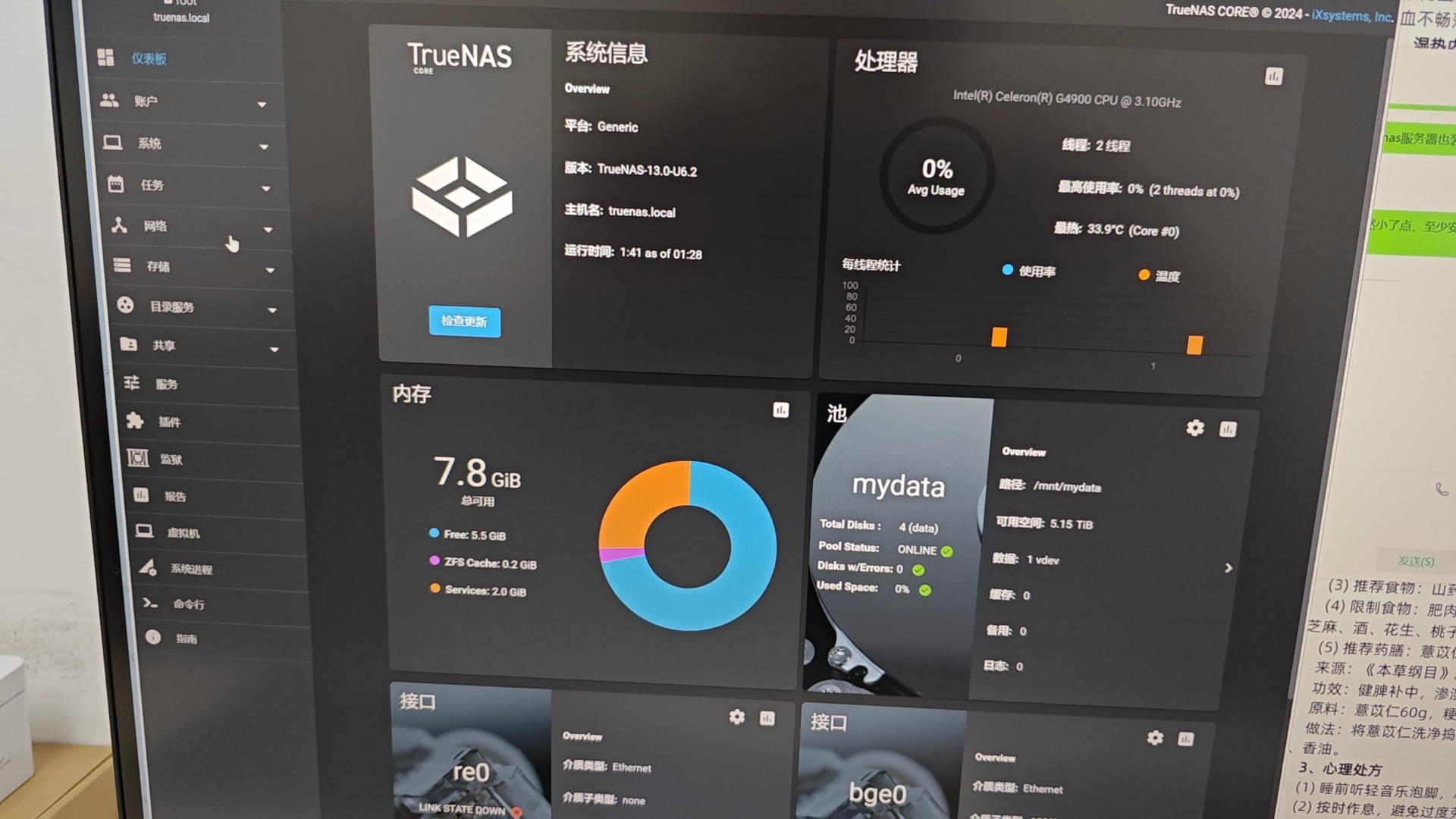
按部就班,安装truenas
最近感觉自己上了年纪,时间与精力不足了,越是如此,有限精力情况下更不敢浪费。
本来想着等他们有顺路车的时候,将老的nas服务器搬到办公室,上午一想,不等了,吃完饭直接塞到儿子的行李箱里,坐公交车就过来了。
从上次经验看,老机器运行Truenas猛如虎的scale版本是不行了,老老实实换回稳定如狗的core版本,看着熟悉的bge网卡代号,感觉日子过得真快啊。
忙了一个下午,计划完成。硬盘虽然小了点,暂且不等不靠,稳步进行。



从应用商店看差距
今天网络打印机到货,在Win10机器上安装的时候,并没有提示下载驱动,而是在HP官网上选择型号后,点击通过Microsoft store安装。
然后不出意外的安装失败。
后来不得不下载离线安装包,一步步按部就班安装完成。
反倒是办公室一台Mac笔记本,人家直接选择安装,自动通过APP store顺利安装完毕。
同是应用商店,还都说苹果霸道,从这上面就看出二者的差距了。
型号混乱的HP打印机
最近一直在准备新办公地点的设备配置,计算机已经到位,下一步关键设备就是打印机了。
原先买的HP1606非常满意,但4年过去了,现在新货已经少见了,便想买一台新型号的双面打印,支持网络的打印机。
在网上搜了一下,发现这样条件的打印机,只HP的型号就非常多。原先HP打印机型号划分如分工一样明确,通过型号代码就能分辨,且每种型号都有当家产品,比如1020,5000Le。
而现在HP打印机种类繁多,功能、规格甚至价格差距并不大,总有一种广种薄收的感觉。
这种挑花眼,不是好事。
东施效颦的Linux桌面版
晚上给伟东那边的Lubuntu系统进行例行升级后,使用htop查看一下系统状态,发现四核心CPU占用都超过60%了。
当时吓了一跳,第一反应是被挂马了。查看异常进程是flurry,网上查了一下,并没有相关资料,只是有些资料提到flurry是一个屏保程序的webgl端口。
于是远程桌面登录到服务器,这才发现原来是儿子写实习报告的时候,使用sac生成地震图表后没有退出,导致系统占用居高不下。
联想到刚给他安装的Chromebox安装桌面版Linux后,有同样的CPU高占用情况,看来问题症结不在硬件系统,而在软件。
我还是那个观点,Linux的优势在服务器,桌面系统简单够用就行,一味模仿Windows来吸引、迎合用户,只能是适得其反,甚至可以说是东施效颦。
彩色电子书阅读器爆发,遥不可及
对彩色电子书阅读器爆发的新闻,我抱怀疑态度。
最终逃不掉泡面盖子命运的电纸书的兴起,依靠的不是电子书商店,否则亚马逊中国也不会草草关门歇业。
很多人购买kindle等电纸书,是为了读书,从TXT到epub格式各类小说,此外还有海量漫画。
而这些绝大多数是不需要色彩的。
能够推动彩色电子书阅读器爆发的,不可能是带不动的短视频,只能是内容更丰富的刊物。
而这不可能是免费的。所以彩色电子书阅读器爆发,遥不可及。
再见,win7
昨天完成了Chromebox系统设置最后一步,通过虚拟机安装win10,并在其中安装了MATLAB等软件,如此一来,Chromebox实现了网络服务器的所有功能,洋垃圾算是物超所值了。
前几天安装Win10并不顺利,无奈只好退而求其次安装win7。这个安装倒是顺利,但进入系统后发现,久违的win7现在已经不堪用了。
安装MATLAB需要挂载镜像,win7没有这个功能,只能下载软件,打开浏览器,是更早的IE,打开一个略微复杂的网页,错误百出。
不堪用不如不用,狠心删掉win7虚拟机,在设置了efi分区后,win10终于可以正常安装运行了。
这个过程其实挺熟悉,从XP升级到win7也是如此。
也许升级到Win11将是必然的,不管我们愿意不愿意。
可用的洋垃圾
周末雨断断续续下,虽不凉爽,好歹能坐得住。利用整装时间,把古籍文献最后步骤棋子图像生成,算是完成了最后的步骤。
然后顺带把Chromebook重新安装调试一番。
虽说是洋垃圾,但带个洋字,也是有身份的垃圾。特别是相比之前我使用的联想M93P,14.5厘米长宽见方的体积,要小上不少,而且自带Type-C显卡接口,关键是4核8线程的CPU是15w的i7。
针对原先CPU占用过高导致系统卡顿,这次换成了轻量级的桌面系统Lubuntu,问题立马解决,无论是sac运行,还是数据传输,已经与server版差距不大。
运行一天,系统稳定,温度不高,洋垃圾算是物尽其用了。
说句题外话,你Linux跟Windows争什么桌面市场啊。
再谈Chromebox
前天晚上是边看亚冠资格赛,边倒腾洋垃圾的,注意力有些不集中。昨天又对应查看了一下相关资料,确定这厮的确是洋垃圾。
虽说买的这台名为Chromebox,运行的系统是Chrome,类似Android,性能要求并不高,但这毕竟是i7,配置最早也是针对超极本的。估计是笔记本表现惨不忍睹,只好半打折半捆绑地卖给华硕了。
这就相当于笔记本运行不了,改手机了,最后直接当洋垃圾处理了。
而它最拉胯的,在于磁盘性能,其实上一代移动处理器也存在这个问题,我现在用的机器便是如此。这应该也是这款洋垃圾刚开始卖的时候,主配都是16G内存的原因。
如果说老黄刀法精准,是有性能作保证,那Intel玩刀,是性能不行,挂羊头卖狗肉。
果然是洋垃圾
儿子实习报告使用Linux系统运行sac,让我刷了一把存在感。我使用的机器大多是server版本的,而sac运行需要桌面版,使用远在伟东的机器总是不方便,于是就惦记着给他装一台便携工作站,为以后学习、工作提供便利。近期网上华硕的Chromebox3很火,回来前下单了一台准系统,今天到货,同时从京东买的内存硬盘也及时送达,下午便组装、安装系统。网上评价这个机器用的最多的形容词是“洋垃圾”,当时想怎么也是Intel的8代i7了,能差哪去,结果装完系统发现,这家伙性能真是够垃圾的。只是单纯运行桌面系统,CPU每个进程都在50%高居不下,这还是Linux系统,换成Win10,下迅雷能热重启并不奇怪。上次看到这么糟糕的CPU,还是P4-1.7G。这Intel混成今天这德性,都是自己做的。
