这个月应用服务器升级,数据库由MySQL更换为Postgresql,数据结构也进行了优化,结合正在进行的一个项目,我也在原先自己数据处理程序的基础上修修补补,保证业务正常运转。
在修补过程中发现,原先的程序实在是糟烂,自己都忍受不了,昨天业务结束 ,就把程序重整了一遍,并把常用数据处理模块加到自定义模型中,程序一下子就变的简洁明了。
这工作其实已经计划了大半年了,一拖再拖,现在看,改进总是好的,下一步就是再把程序由文件管理数据,纳入到数据库管理,下个月完成。
也就是今年完成。日子真的很快。
分类: IT天地
尚不靠谱本地RAG
昨天测试了一下大模型的RAG助理,问了一个简单的问题:《三国演义》的作者是谁。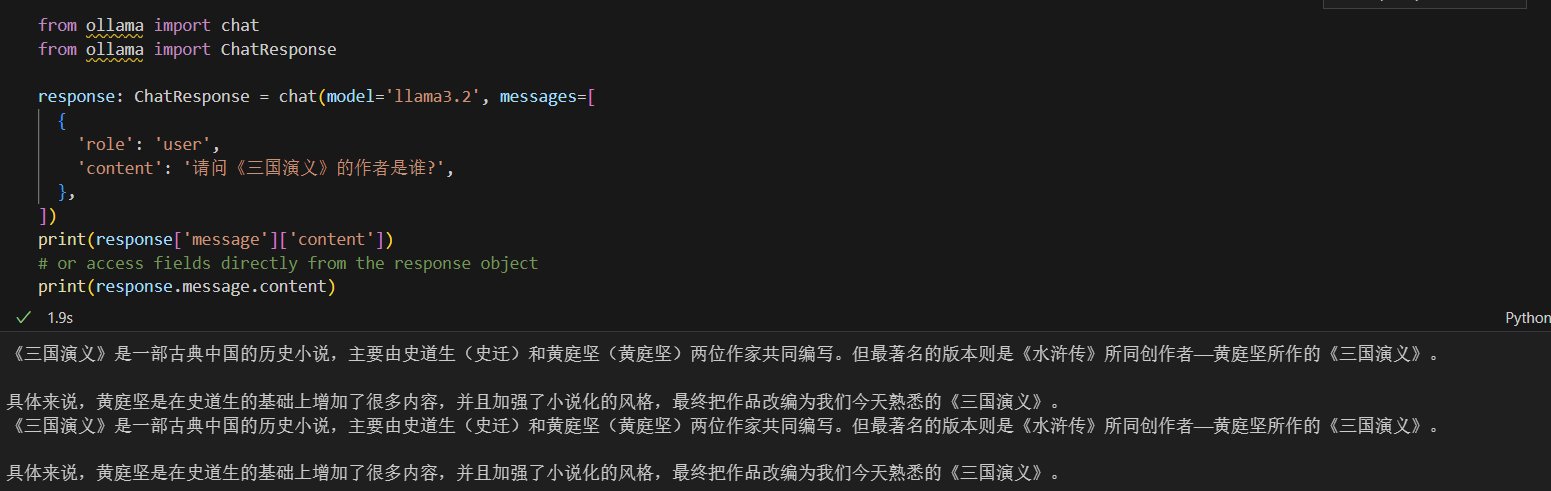 Llama3.2的回答真是史屎级的回答,可谓是震裂三观。考虑到人家是外国模型,毁中国历史文化情有可原,换成国产千问,同样是胡说八道,信口开河。
Llama3.2的回答真是史屎级的回答,可谓是震裂三观。考虑到人家是外国模型,毁中国历史文化情有可原,换成国产千问,同样是胡说八道,信口开河。
于是将正确答案录入到内嵌模型中,千问立马变脸,不止答案正确,而且给出了相关创作背景。而老外依然是继续胡说八道。
这也验证了我之前的判断,那就是所谓RAG依靠的还是大模型,所谓内嵌助理,只是助理,提醒、辅助而已。就像千问显然其大模型中有这个知识,但是要定位到准确知识,则需要结合内嵌服务器。而llama本身就没有知识内容储备,有助理也只是摆设。
下载ESXi费周折
昨天零碎装起来机器,是用来当做虚拟机的。本来计划安装最新版ESXi8,但没想到在VMware登录的时候,居然跳到博通的官网上,而且还不认我原先的账户。
记得有些年了,一个同事孩子在美国毕业后进入博通公司工作。当时那个同事在跟我强调是博通而不是高通后,发现我居然知道这个公司,还颇为惊讶。
知道博通是因为用的它产品不少,从最早当下载服务器的迈拓硬盘盒子,到后来第一个nas系统的网卡,最熟悉的还是树莓派的处理器。
好容易注册成功后,又找不到下载的入口。就在我打算放弃,使用手头老版本5.x版本的时候,居然误打误撞进去了。下载完后,刷新页面,我的下载里面又找不到了。
看来博通收购VMware后,让我等免费用户薅羊毛,是真不情愿啊。
“强大”的客户端
周六外甥开始担心家里机器里面数据的安全,于是便搭建了一个rsync服务器端,做数据的同步。
同步工作自然少不了定时,我以往都是用crontab的,这次听外甥提到他用的青龙面板功能非常强大,于是便想做一个docker镜像。
结果没想到一天就折腾进去了。
首先自然是网络阻碍,搭建半道就卡住了。于是绕道而行,在自己购买的云服务器上运行容器,然后通过容器备份为镜像下载。结果第一个1G内存的服务器崩掉了,换了一个2g内存的倒是顺利完成了,生成的镜像一看,好家伙,1G大小的镜像,难怪把云服务搞死了。
想到前几天恢复云服务器的MySQL数据,200M的数据,两个客户端半道死机,最后一个source命令,几秒钟搞定。
算了,还是安心用技术活吧。
升级主机显卡大头
淘宝不比京东,机器升级的核心显卡迟迟到位。别看个头小,如果不是二手货,价格比那一堆还高。
老机器用了快两个月,慢点还能忍受。10月底虽然回家,工作基本是平移的,不比不知道,同样是5年前的机器,R3还是没法跟R7比的。
机器安装顺利,速度提升显著,NAS备份数据也把交换机速度拉满了。
显卡最后买的是没有阉割的8G版3050,功耗略高,虽然性能提升不大,主要目的是测试一下RAG在单机版AI助理方面的应用。这款显卡的性能,应该与主流独显笔记本相当,结合脱机版大模型与向量数据库,如果能够起到AI助理的作用,已然足够了。


感觉不要钱的傲腾
原先纯属爱好的时候,特别喜欢折腾计算机便宜配件,看到时兴便宜的宝贝就买来测试一下,现在反而很少关注了。从freenas起,我一直用U盘做系统盘,上个月安装nas机器,发现官方已经不再推荐使用U盘,估计目前U盘质量随着价格滑落而大幅跳水。不过使用SSD硬盘做系统盘,有个挺恶心人的地方,truenas跟exsi不一样,系统盘只能用来安装系统用,即便剩余再多空间也没法用。上网搜了半天,发现现在很多人用一款傲腾当SSD系统盘用,Intel独家生产,nvme接口,关键是便宜,16G才不到13块钱。就这钱还犹豫什么,立马下单,到货后安装一切正常,这比U盘可强多了。久违的乐趣也回来了。
困倦中的技术收获
最近感觉精力不足,昨晚到了10点就困得脑子不听使唤,便试着把外甥前段时间提及的文本转语音ChatTTS安装调试。
系统安装除了GitHub连接不上都还顺利,老办法打包下载,上传服务器后一马平川。系统运行后,界面也很简陋,但简单转换一段文字后,整个人顿时又精神起来。转换后的语音虽然称不上抑扬顿挫,却也十分自然,这是以往使用过的系统,那种硬件发声所欠缺的。
在安装过程中,无意中浏览到苹果系统居然也有自己编译的katago,这意味着基于M系列处理器苹果机器,可以解决目前AI应用存在的软硬件互相掣肘的问题。
今天特意到办公室,用外甥的M1处理器的老机器上安装katago,并进行了benchmark测试。
最终结果很失望,失望的不是结果,M1的成绩相当于1660,已属不易,但问题出在katago是基于opencl编译的,也就是说苹果处理器再强力,还是要受到开发环境的制约。
由此看来,AI发展还得看黄厂长的脸色。
决定放弃truenas scale
今天在折腾了一个白天后,决定放弃truenas scale了。
这truenas的开发商或者说运营商,发行基于Debian的scale版本,是想学苹果和谷歌,打造自己的应用生态圈,但他又没有那个能力,所以k8s应用只能依托GitHub和docker,而就目前国内的网络环境而言,无异于作茧自缚。
同时,打着安全性的旗号,scale阉割了Debian的开放性,甚至应用目录里默认把非官方的社区版truecharts都屏蔽掉了,因为双方对下一步发展已经有了分歧。
目前看,唯一比core版本强的,就是虚拟机管理了。
还是切回core版,安安心心当好后勤数据管理管家吧。
服务器主板贵有贵道理
当年在单位自开发系统,到科技市场,看着超微、泰安服务器主板及格,想想可怜巴巴的预算,只能是吃不着葡萄说葡萄酸,自我安慰“老子重系统不重硬件”。这次安装机器才明白,这服务器主板贵有贵的道理。光这自带的IPMI就省却了太多周折,让我大开眼界。本次系统安装因为涉及到NVMe硬盘启动,需要在bios中进行设置。我想这IPMI既然都需要在bios中设置,这设置bios你该管不着了吧,正在庆幸自己买了一根vga线备用时,随手点了一下del,发现熟悉bios界面已经出现在ipmi管理界面中。真是贫穷限制了想象力。装机加系统本来昨天就该完成的,只是久不装机器,手不止是生了,还娇气了,原先徒手就能把铜柱拧到机箱上,结果只拧了四个就扭不动了,只好从网上紧急下单买了一个工具箱,今天才完成工作。

怀念Delphi
因为最近一项重要工作是要做前端,上周跟外甥交流一下,结果他好家伙给我推荐了一大堆免代码框架,经过周末两天的挑三拣四,最后选定了Nocobase。
我其实要的很简单,只是一个数据展示、录入的交互界面的开发工具,这也让我无比怀念Delphi,onshow,onclick,多么简单。
其实当年李维主推的DBExpress接口是很超前的,虽然单向数据集有着诸多限制,但一个统一的接口,多种数据库的通道就构成了。
结果相信大而不死的delphi,最后还是死在网络时代。