在中日围棋擂台赛初期的一次电视转播中,当时年富力强的王汝南八段在挂盘讲解的时候,就一个劫进行了围棋技术普及,大意是:打劫不一定是非要打赢的,围绕这个劫在寻劫过程中获取足够的利益就可以了。
当时虽然开始痴迷围棋,但还是理解不了。后来虽然围棋欣赏水平有所增长,但对打劫依然停留在寻求刺激的层面上。
但那天晚上katago与leelazero的对局,给了我一次彻底地实战指导。这也是我这几天一直寻求找回这局棋谱的原因。
棋谱最终还是遗失了。而我的水平还达不到复盘的水平,只能先暂且记录一下吧,好在以后这样的对局还是会层出不穷的。
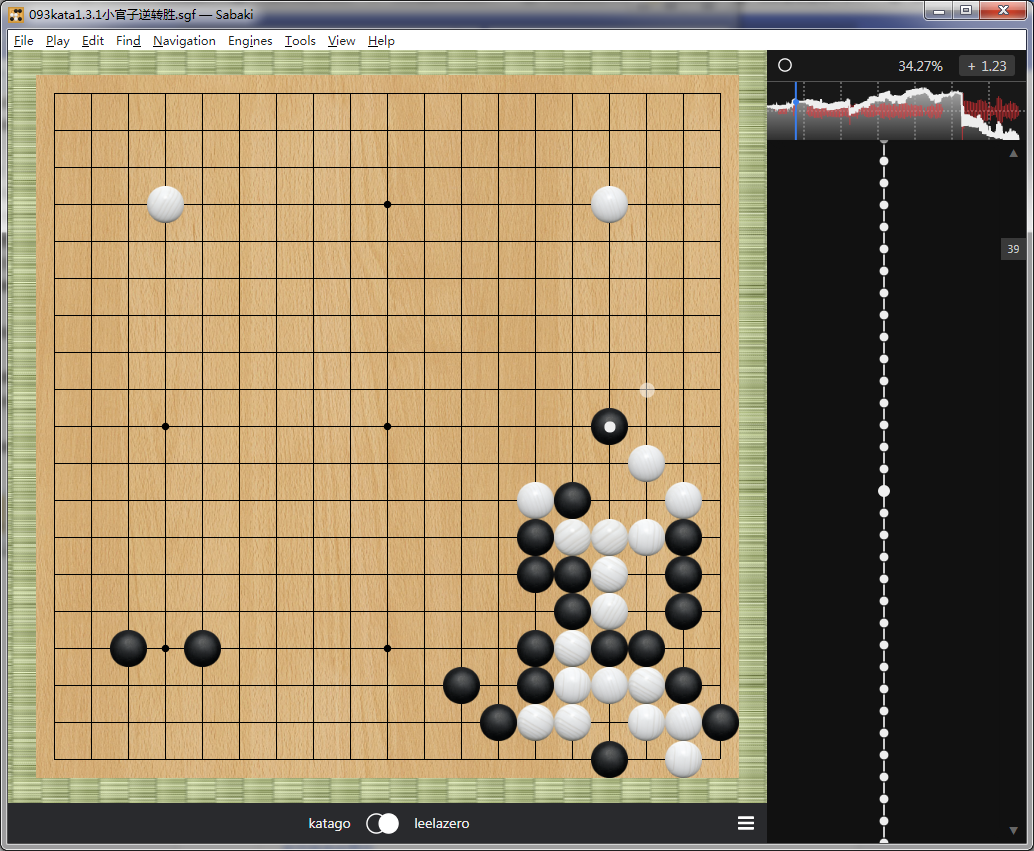
那盘棋执黑的katago开局不出所料中了芈刀,出现类似的局面,只不过左下角是二间守角。这个方向上的守角,katago自认胜率还不至于低到三成。
之后leelazero打入下方,黑棋直接从厚势方先点出头白棋,后夹下方白棋破眼攻击。而269权重的leelazero似乎没有前两个权重那样强硬,没有正面反击而选择向中腹出头。katago则利用左侧攻击顺势进入白棋左上角,并自认胜率持平,但leelazero认为形势不错,保持在7成。
左上角后来形成了一个黑棋的紧气劫,开劫之前,katago先将芈刀弱侧右侧两个孤子联络,然后开劫。这时候双方胜率突然一致起来,katago胜率升至七成。
之后的劫争中,katago并不急着打赢左上角的劫,而是通过芈刀形成的厚势继续有条不紊地缠绕攻击打入的白棋,胜率逐渐上升,最后左上角劫争已经不再重要,在将纵贯大半个棋盘的白棋大龙包围后,leelazero中盘认输。
如果是上次观看katago通过两个缓气劫逆转是刺激,那这局棋就是精彩。
飞扬围棋里面是分为涨棋党和书脊党,现在看AI群里面,也是分为涨棋帮和遛狗帮。我没有涨棋的奢望,也不图遛狗的场面。能通过AI找寻一些对围棋乐趣,足矣。
